Towards an Unsupervised Method for Model Selection in Few-Shot Learning
Published at : 02 Nov 2021
Our paper presented at the ICML 2020 - Fourth Lifelong Learning Workshop.
Link to paper: https://openreview.net/pdf?id=wGO2NgC-ua9
TL;DR: Do we need labeled data from held-out classes for model selection in Few-shot Meta-Learning? Our method doesn’t. Based on the learned space of representation and using all available data for training, results show it can outperform meta-validation.
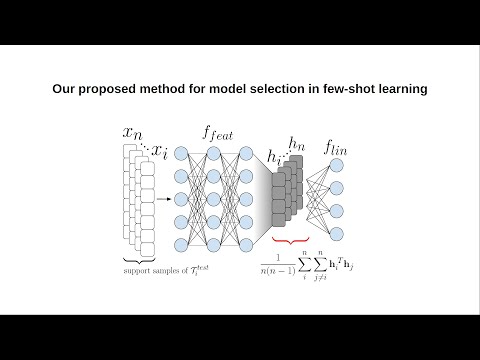
Abstract:
The study of generalization of neural networks in gradient-based meta-learning has recently generated great research interest. Previous work on the study of the objective landscapes within the scope of fewshot classification empirically demonstrated that generalization to new tasks might be linked to the average inner product between their respective gradients vectors (Guiroy et al., 2019). Following that work, we study the effect that meta-training has on the learned space of representation of the network. Notably, we demonstrate that the global similarity in the space of representation, measured by the average inner product between the embeddings of meta-test examples, also correlates to generalization. Based on these observations, we propose a novel model-selection criterion for gradient-based meta-learning and experimentally validate its effectiveness. Our paper presented at the 4th Lifelong Learning Workshop of ICML 2020.

Raheem DeVaughn - Customer (Lyrics)

What is Potency? An Introduction

Concerning the anti-authority of the Antichrist

Revel In Gore official music video

Are You Stronger Than Average? (Noob To Freak)

Patrick Patrikios | You Should (1-hour version)

Kapustin Motive Force Op.45

I Do Not Understand Hotline Miami 2

How a wound heals itself - Sarthak Sinha

Even If

Xzibit- Alcoholic (uncensored, original version with lyrics)

SIDEMEN vs ROBUST! (GTA 5 Funny Moments)

SHEILA ON 7 - J.A.P

The Body in the Sports Bag - Crime Investigation Australia | Murders Documentary | True Crime

Answerable to and Answerable for usage in Spoken English

What if Coronavirus Disappeared? + more videos | #aumsum #kids #science #education #children

فيلم الأثارة و التشويق الكوري A DAY 2017 - HD720

Reality Based Heart Touching TikTok Videos | TikTok Compilation 💔

Know Your Value

Venerate | Meaning with examples | My Word Book

#2 Iowa vs Purdue Highlights | College Football Week 7 | 2021 College Football Highlights

おつかれさまです!w/Selly、めと

So many parents have been playing the’Nutella prank’ on their kids😂

Dare To Differ

Chiefly

To heighten.

NEW FESTIVAL GOWTHER & HOWSER LEGENDARY SUMMONS! Seven Deadly Sins: Grand Cross

We need to radically change education | Jean Philippe Rosier | TEDxIEMadrid

Funniest & Cutest Labrador Puppies #2 - Funny Puppy Videos 2020

🔴 LIVE at Cherokee Casino in Ramona w/ Slot Queen!

How The Space Shuttle Started Its Engines And Launched

BEST TIPS & TRICKS IN ANIME TAPPERS! FAST TAPS AND YEN! OVERPOWERED😱 - Roblox Anime Tappers
![Nav - Some Way ft. The Weeknd (Lyrics) "I think your girl, fell in love with me" [TikTok Song]](https://ytimg.googleusercontent.com/vi/zCq7np46LpQ/mqdefault.jpg)
Nav - Some Way ft. The Weeknd (Lyrics) "I think your girl, fell in love with me" [TikTok Song]

Hippie Sabotage - DIFFERENT

How To Enroll in IFCU's Online Banking
![Måneskin - Beggin' (Lyrics)"I'm beggin', beggin' you" [TikTok Song]](https://ytimg.googleusercontent.com/vi/2Ld0IfAfqPc/mqdefault.jpg)
Måneskin - Beggin' (Lyrics)"I'm beggin', beggin' you" [TikTok Song]

Macedonian Museum of Contemporary Art Thessaloniki: History

Mooji - Can I Found MYSELF ? AM I Duality or Non-duality Or Both ? DEEP INQUIRY

The Clash - Should I Stay or Should I Go (Official Audio)

The Georgia Thunderbolts - Lend A Hand (Official Music Video)

Durand Jones & The Indications - Is It Any Wonder? - 8/28/2017 - Paste Studios, New York, NY

Compras na Shein: vale a pena? Tempo de entrega, preços e qualidade!

The Appearing Official Trailer 2013

12 Most Incredible Recent Discoveries
![Arvo Pärt - Da Pacem [Estonian Philharmonic Chamber Choir/Paul Hillier] (2006)](https://ytimg.googleusercontent.com/vi/YOpa5Ec3i4s/mqdefault.jpg)
Arvo Pärt - Da Pacem [Estonian Philharmonic Chamber Choir/Paul Hillier] (2006)

Disregard - Sacrifice (Guitar Playthrough)

I'm Building A $1,000/Month Passive Income Dividend Portfolio From $0

Methods in Java Tutorial
